引言
大家都在想 Claude Code 为什么如此出色,为什么能在智能体领域表现优异。其实,答案很简单:Agent Loop 就是你需要的所有内容了。
但"简单"不等于"简陋"。Agent Loop 这个概念人人都懂——观察、思考、行动、反馈的循环——可为什么偏偏 Claude Code 做得最好?答案藏在 queryLoop() 的源码里。
什么是 Agent Loop?
Agent Loop 是一种基于循环的智能体架构,它允许智能体在不断地与环境交互中选择不同决策和使用工具。业界常见的 Agent Loop 包括以下几个步骤:
1. agent 得到输入
2. agent 分析输入并思考选择工具
3. agent 执行动作
4. agent 获取反馈并更新策略
5. 重复以上步骤,直到任务完成借用智谱和 Anthropic 的图片,我们可以更直观地理解 Agent Loop 的流程:
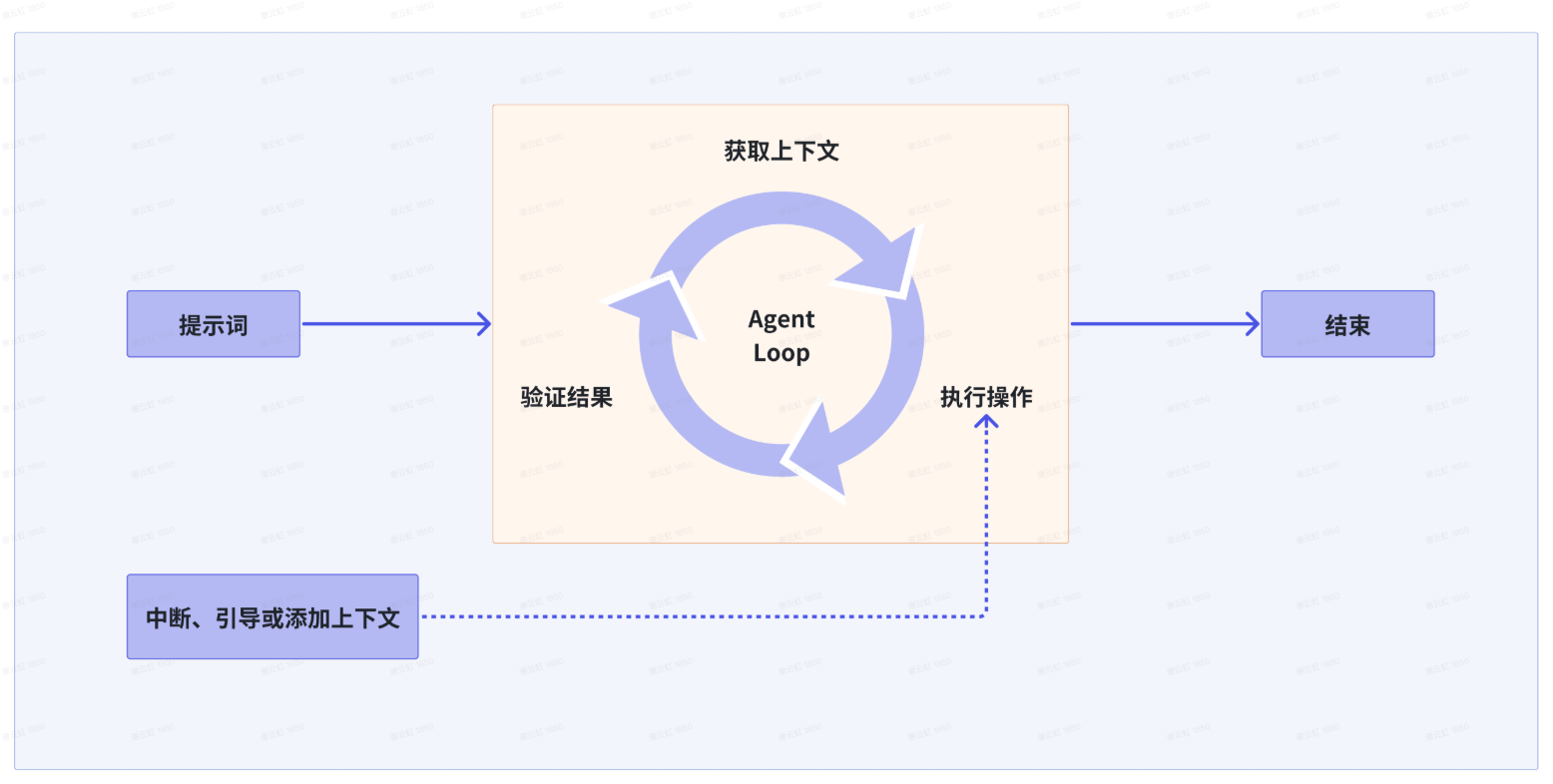
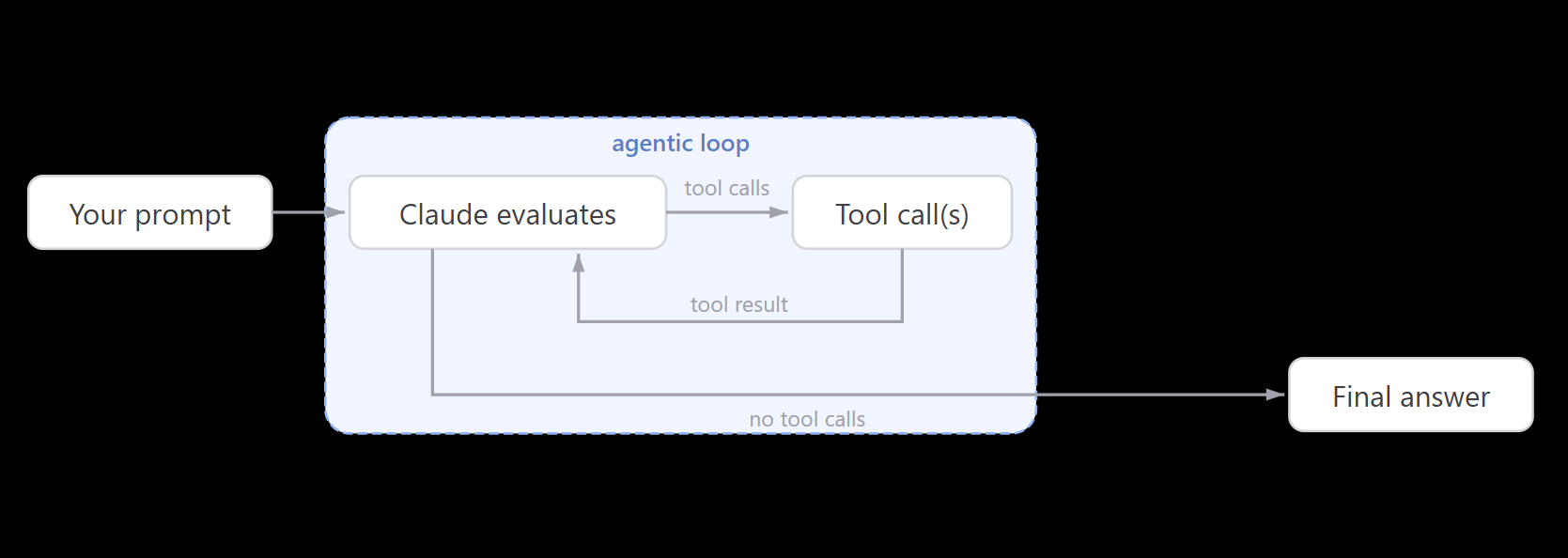
概念上,每个 AI 编程工具都在做这件事。但执行的深度决定了结果的差异。
为什么 Claude Code 出色?
答案藏在 queryLoop() 的源码里。这个位于 query.ts:241 的函数,是一个约 1400 行的 while(true) 循环,是 Claude Code 的真正引擎。外层 QueryEngine 负责会话管理,内层 queryLoop() 负责核心循环。
同一个 Agent Loop 五步,Claude Code 每一步都比别人做得深。我们逐步来看。
步骤 1:agent 得到输入——输入远不止用户消息
普通的 Agent Loop 里,"得到输入"就是拿到用户的文字消息。但在 Claude Code 的 queryLoop() 中,模型拿到的"输入"是一整套精心组装的上下文包:
消息准备管线:每轮迭代开头,queryLoop() 不是直接把历史消息丢给模型,而是经过四级处理:
// query.ts — 每轮迭代开头的消息准备
let messagesForQuery = [...getMessagesAfterCompactBoundary(messages)]
// 1. Tool Result Budget — 裁剪过大的工具输出,防止撑爆上下文
messagesForQuery = await applyToolResultBudget(messagesForQuery, ...)
// 2. History Snip — 剪除过长的历史细节
const snipResult = snipModule!.snipCompactIfNeeded(messagesForQuery)
// 3. Microcompact — 缓存编辑级别的微压缩
const microcompactResult = await deps.microcompact(messagesForQuery, ...)
// 4. Autocompact — 摘要级上下文压缩(当 token 接近上限时触发)
const { compactionResult } = await deps.autocompact(messagesForQuery, ...)附件系统(Attachments):模型的输入不只是消息历史,还有从各种来源收集的附件:
// query.ts — 工具执行后,收集所有附件注入到下一轮输入中
// 文件变更附件(其他进程编辑的文件会被检测到)
for await (const attachment of getAttachmentMessages(...)) {
toolResults.push(attachment)
}
// Memory 预取(异步加载的记忆文件,与模型流式输出并行)
if (pendingMemoryPrefetch?.settledAt !== null) {
const memoryAttachments = await pendingMemoryPrefetch.promise
for (const memAttachment of memoryAttachments) {
toolResults.push(createAttachmentMessage(memAttachment))
}
}
// Skill 发现预取(发现可用的技能,97% 在模型输出期间就完成了)
if (skillPrefetch && pendingSkillPrefetch) {
const skillAttachments = await skillPrefetch.collectSkillDiscoveryPrefetch(...)
toolResults.push(...skillAttachments)
}
// 队列中的命令(后台任务完成通知、用户排队消息)
const queuedCommandsSnapshot = getCommandsByMaxPriority(sleepRan ? 'later' : 'next')
.filter(cmd => isMainThread ? cmd.agentId === undefined : ...)系统提示词的动态构建:
// 每轮都重新拼接完整的系统提示词
const fullSystemPrompt = asSystemPrompt(
appendSystemContext(systemPrompt, systemContext)
)这意味着什么? 模型每一轮看到的不是"上次对话 + 用户新消息"这么简单,而是一个经过压缩、裁剪、附件注入、技能发现的完整工作上下文。其他工具给模型看的是流水账,Claude Code 给模型看的是精编杂志。
步骤 2:agent 分析输入并思考选择工具——思考过程的保护
这一步的核心是调用 Claude API。大多数工具就是"发消息,等回复"。Claude Code 在这一步做了两件关键的事:
流式接收 + 流式工具执行:模型在流式输出 tool_use 块时,Claude Code 不等模型输出完毕,就开始执行工具了:
// query.ts — 边流式接收,边执行工具
for await (const message of deps.callModel({...})) {
if (message.type === 'assistant') {
const msgToolUseBlocks = message.message.content.filter(c => c.type === 'tool_use')
// 模型刚输出一个 tool_use 块,立即加入执行队列
for (const toolBlock of msgToolUseBlocks) {
streamingToolExecutor.addTool(toolBlock, message)
}
// 同时获取已完成工具的结果
for (const result of streamingToolExecutor.getCompletedResults()) {
yield result.message
}
}
}模型过载降级:当主模型过载返回错误时,queryLoop() 会自动切换到 fallbackModel 继续工作:
// query.ts — 模型降级
const callModel = async (params) => {
try {
return await deps.callModel({ ...params, model: currentModel })
} catch (error) {
if (isOverloaded(error) && fallbackModel) {
return await deps.callModel({ ...params, model: fallbackModel })
}
throw error
}
}这意味着什么? "分析并思考"这一步不是同步等待——模型在思考的时候,工具已经在执行了。主模型过载时,用户不会看到报错,系统默默切换模型继续工作。
步骤 3:agent 执行动作——智能并发调度
这是工程复杂度最高的一步。Claude Code 不是简单地"一个一个执行工具",而是做了智能批处理:
// toolOrchestration.ts — 将工具调用分为并发安全的批次
function partitionToolCalls(toolUseMessages, toolUseContext): Batch[] {
return toolUseMessages.reduce((acc, toolUse) => {
const isConcurrencySafe = tool?.isConcurrencySafe(parsedInput.data)
// 连续的只读工具合并到同一个批次,并发执行
if (isConcurrencySafe && acc[acc.length - 1]?.isConcurrencySafe) {
acc[acc.length - 1]!.blocks.push(toolUse)
} else {
// 有副作用的操作单独成批,串行执行
acc.push({ isConcurrencySafe, blocks: [toolUse] })
}
}, [])
}逻辑很清晰:
- Read、Glob、Grep 等只读工具 → 连续的合并到一批,并发执行
- Write、Edit、Bash 等有副作用的工具 → 串行执行,保证安全
- 每批之间 → 串行,前一批的结果影响后一批的执行
工具执行中的权限检查:每个工具执行前都要过权限关:
// toolExecution.ts — 权限检查 → hooks → 执行
for await (const update of streamedCheckPermissionsAndCallTool(
tool, toolUseID, toolInput, toolUseContext, canUseTool, ...
)) {
yield update
}工具每轮结束后刷新:MCP 服务器可能在执行过程中新连接,所以每轮结束时刷新可用工具列表:
// query.ts — 刷新工具列表
if (updatedToolUseContext.options.refreshTools) {
const refreshedTools = updatedToolUseContext.options.refreshTools()
if (refreshedTools !== updatedToolUseContext.options.tools) {
updatedToolUseContext = { ...updatedToolUseContext, options: { ...updatedToolUseContext.options, tools: refreshedTools } }
}
}这意味着什么? 如果模型决定同时读取 10 个文件,这 10 个 Read 调用并发执行。如果接着要写 3 个文件,写操作会串行排队。读取的安全性由 isConcurrencySafe 判断,开发者不需要手动标注。
子代理系统(Agent Tool):除了内置工具,Claude Code 还能通过 Agent 工具派生子代理。子代理有独立的上下文,但共享父代理的基础设施:
// createSubagentContext.ts — 创建隔离的子代理上下文
export function createSubagentContext(parentContext, agentId, agentType) {
return {
...parentContext,
agentId,
agentType,
// 子代理的 setAppState 是 no-op,防止污染父状态
setAppState: () => {},
// 但 setAppStateForTasks 仍然指向根 store
setAppStateForTasks: parentContext.setAppStateForTasks,
// 独立的权限追踪
localDenialTracking: createDenialTrackingState(),
// 继承父代理的系统 prompt 以共享缓存
renderedSystemPrompt: parentContext.renderedSystemPrompt,
}
}子代理支持两种模式:Fork(全新实例,独立上下文)和 Resume(恢复之前的子代理,保持状态)。子代理的 setAppState 是空操作,防止它污染父代理的 UI 状态;但 setAppStateForTasks 仍然指向根 store,这样子代理可以注册跨生命周期的任务。
步骤 4:agent 获取反馈并更新策略——反馈的丰富度决定了下一轮的质量
工具执行完毕后,queryLoop() 不是简单地把结果拼回去,而是经过一系列处理,构建出一个极其丰富的反馈包:
工具结果摘要(Tool Use Summary):模型使用的工具和结果太多时,会用 Haiku 模型生成一个摘要,不阻塞下一轮循环:
// query.ts — 工具摘要异步生成
nextPendingToolUseSummary = generateToolUseSummary({
tools: toolInfoForSummary, // 工具名、输入、输出
signal: abortController.signal,
lastAssistantText, // 最后一条 assistant 消息的文本
}).then(summary => summary ? createToolUseSummaryMessage(summary, toolUseIds) : null)
.catch(() => null)这个摘要在下一轮迭代中 yield 给 UI。也就是说,上一轮的工具摘要与下一轮的模型输出是并行的。
错误恢复——反馈不是终点,是起点:当反馈中包含错误时,queryLoop() 不会把错误抛给用户,而是注入回循环让模型修正:
- max_output_tokens 截断 → 注入 meta 消息让模型"从中断处继续",最多重试 3 次
- prompt-too-long → 先 withhold 错误,尝试响应式压缩后 continue
- stop hook 阻断 → 将错误注入循环让模型修正行为
// max_output_tokens 截断恢复
const recoveryMessage = createUserMessage({
content: `Output token limit hit. Resume directly — no apology, no recap.
Pick up mid-thought if that is where the cut happened.`,
isMeta: true,
})
state = { messages: [...messagesForQuery, ...assistantMessages, recoveryMessage], ... }
continue响应式压缩:如果 API 返回 413(上下文太长),错误被"扣留"(withhold),系统先尝试压缩再重试:
// 错误被扣留,不立即 yield
if (reactiveCompact?.isWithheldPromptTooLong(message)) { withheld = true }
if (isWithheldMaxOutputTokens(message)) { withheld = true }
if (!withheld) { yield yieldMessage }还有熔断器:连续 3 次压缩都失败,就停止尝试,避免浪费 API 调用:
// autoCompact.ts — 源码注释
// 1,279 sessions had 50+ consecutive failures (up to 3,272)
// wasting ~250K API calls/day globally
const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3这意味着什么? 反馈不只是"工具返回了什么",而是经过摘要、错误恢复、压缩保护后的高质量反馈。模型在下一轮拿到的不是原始工具输出,而是经过精心处理的上下文。
步骤 5:重复以上步骤,直到任务完成——状态管理的精巧设计
循环的"重复"看似简单,但 1400 行的循环如何不变成面条代码?关键在状态管理。
queryLoop() 把状态分为两类:
不可变参数(整个查询期间不变):
const { systemPrompt, userContext, systemContext, canUseTool, fallbackModel, maxTurns } = params可变状态(每次 continue 时整体替换):
type State = {
messages: Message[] // 消息列表
toolUseContext: ToolUseContext // 工具上下文
autoCompactTracking: ... // 压缩追踪
maxOutputTokensRecoveryCount: number // token 恢复计数
hasAttemptedReactiveCompact: boolean // 是否尝试过响应式压缩
pendingToolUseSummary: Promise | undefined // 待处理的工具摘要
turnCount: number // 当前轮数
transition: Continue | undefined // 上一次 continue 的原因
}每个 continue 站点不是零散地修改变量,而是整体替换 State 对象:
const next: State = {
messages: [...messagesForQuery, ...assistantMessages, ...toolResults],
toolUseContext: toolUseContextWithQueryTracking,
turnCount: nextTurnCount,
...
transition: { reason: 'next_turn' }, // 记录为什么 continue
}
state = nexttransition 字段记录了"上一次为什么 continue",用于防止无限循环——比如已经 drain 过 collapse 但仍然 413,就不会再 drain 了。
终止条件:循环只有两种正常退出:
return { reason: 'completed' }— 模型输出end_turn,无工具调用return { reason: 'max_turns' }— 达到最大轮数限制
这意味着什么? 1400 行的 while(true) 循环没有变成意大利面条,归功于"不可变参数 + 可变 State 整体替换"的设计。每次迭代开始时,所有状态都是从 State 解构出来的,保证读到的是一致快照。
总结:Agent Loop 的实现深度决定智能体的能力上限
回到标题:Agent Loop is All You Need。
这句话有两层含义:
概念上:Agent Loop 的五步确实是智能体的核心架构,不需要更花哨的框架。
实践上:知道 Agent Loop 的概念和真正实现好一个 Agent Loop 是完全不同的事情。Claude Code 的出色不是因为有什么神秘的算法,而是在每一步都比别人做得更深:
| 步骤 | 普通实现 | Claude Code |
|---|---|---|
| 1. 得到输入 | 用户消息原文 | 四级压缩 + 附件注入 + Memory/Skill 预取 |
| 2. 分析思考 | 同步调 API | 流式接收 + 流式工具执行 + 模型过载自动降级 |
| 3. 执行动作 | 全部串行 | 只读并发 + 写入串行 + 子代理 Fork/Resume + 工具列表动态刷新 |
| 4. 获取反馈 | 工具结果原文 | 摘要生成 + 错误 withhold + 响应式压缩 + 熔断器 |
| 5. 循环状态 | 散变量 | 不可变参数 + State 对象整体替换 + transition 防死循环 |
Agent Loop 的概念是简单的。但把简单的事做到极致——这就是 Claude Code 出色的原因。
Astrcode 的 Agent Loop:为什么不能照搬 Claude Code
Claude Code 的 queryLoop() 是一个约 1400 行的 while(true) 函数。它工作得很好——在 TypeScript + Node.js 单线程环境下。但如果你想把同样的架构搬到 Rust 里,你会遇到根本性的问题。
为什么 Rust 不能写 1400 行巨型循环
1. 所有权系统不允许零散的状态修改
Claude Code 的 queryLoop() 里到处是散变量和就地修改:
// Claude Code — 散落在循环体各处的状态修改
messages.push(assistantMessage)
state = { ...state, transition: { reason: 'next_turn' } }
pendingToolUseSummary = generateToolUseSummary(...)
reactiveCompactAttempts++TypeScript 不管你什么时候改、在哪改、谁在改。Rust 的所有权系统会问:这个 messages 的可变引用是不是唯一?state 被 continue 传到下一轮后,旧引用还在吗?1400 行循环里有 7 个 continue 站点,每个都可能持有悬挂引用——编译器会让你把每个分支都证明清楚。
2. 错误处理不允许忽略边界
Claude Code 的错误恢复是隐式的——try/catch 捕获错误,然后根据类型决定是 continue 还是 throw:
// Claude Code — 隐式错误分类
try {
return await deps.callModel({ ...params, model: currentModel })
} catch (error) {
if (isOverloaded(error) && fallbackModel) { ... }
throw error
}Rust 没有 try/catch,只有 Result<T, E> 和 ? 运算符。每个错误都必须显式处理——要么 match,要么 ? 传播。如果你把 7 种错误恢复路径塞在一个函数里,match 的嵌套会让代码不可读。Astrcode 的做法是把错误恢复分散到 turn_runner 的结构化 'step: loop 里,每个 continue 对应一个明确的恢复路径。
3. 并发模型完全不同
Claude Code 跑在 Node.js 单线程上,不需要考虑并发安全。但 Rust 的 async 运行时(tokio)天然支持多任务并发,你需要处理:
// Astrcode — 同一 session 的并发提交保护
let was_idle = session.running.swap(true, Ordering::SeqCst);
if !was_idle { return Err(TurnConflict); }这种问题在 Claude Code 里根本不存在——同一时刻只有一个事件循环在跑。
4. 编译时间 vs 重构代价
1400 行的泛型函数在 TypeScript 里改起来很快——改一处,跑一下,看报错。Rust 的编译时间不允许这种"试错式开发"。一个 1400 行的 async 函数改一行可能导致 30 秒的重编译。模块化拆分不是为了好看,是为了让编译器只重编译改动的模块。
Astrcode 的 Agent Loop 设计
因为这些语言层面的约束,Astrcode 的 AgentLoop 走了完全不同的路——8 个独立组件 + Builder 组装。
pub struct AgentLoop {
factory: DynProviderFactory, // LLM Provider 工厂
capabilities: CapabilityRouter, // 工具注册表
policy: Arc<dyn PolicyEngine>, // 策略引擎(trait,可插拔)
approval: Arc<dyn ApprovalBroker>, // 审批代理(trait,可插拔)
prompt: PromptRuntime, // Prompt 组装
context: ContextRuntime, // 上下文构建
compaction: CompactionRuntime, // 压缩管理
hooks: HookRuntime, // 生命周期钩子
request_assembler: RequestAssembler, // 请求装配
}这不是过度设计——是 Rust 的语言特性逼出来的最佳实践:
| Rust 约束 | Astrcode 的应对 | Claude Code 为什么不需要 |
|---|---|---|
| 所有权要求可变引用唯一 | 每个组件独立持有自己的状态 | 单线程,随便改 |
| Result 必须显式处理 | 每个模块有明确的错误类型 | try/catch 隐式分类 |
| 编译时间惩罚巨型函数 | 拆成独立 crate 并行编译 | V8 JIT 不需要编译 |
| async 并发需要同步 | RwLock<Arc<AgentLoop>> + CancelToken | 单线程事件循环 |
组装流程:Builder 模式 vs 巨大构造函数
Claude Code 把 25+ 个参数一次性塞进构造函数:
const engine = new QueryEngine({
cwd, tools, commands, mcpClients, agents,
canUseTool, getAppState, setAppState,
customSystemPrompt, appendSystemPrompt,
userSpecifiedModel, fallbackModel, thinkingConfig,
maxTurns, maxBudgetUsd, taskBudget, jsonSchema,
// ... 还有十几个参数
})Astrcode 用 Builder 模式分层组装,每层只关心自己的配置:
AgentLoop::from_capabilities_with_prompt_inputs(factory, capabilities, ...)
.with_policy_profile(active_profile) // 策略配置
.with_hook_handlers(hook_handlers) // 生命周期钩子
.with_auto_compact_enabled(...) // 压缩配置
.with_policy_engine(policy) // 策略引擎
.with_approval_broker(approval) // 审批代理Builder 模式在 Rust 中不只是风格偏好——它是用类型系统保证构造完整性的方式。from_capabilities() 返回一个缺少 policy 的 AgentLoop,你可以先配置 compaction 再配 policy,编译器保证你不会忘记某个必填项。而 Claude Code 的构造函数参数都是 optional 的——忘了传 canUseTool?运行时才知道。
热替换:Rust 给了 Claude Code 做不到的能力
Claude Code 的 QueryEngine 创建后就是固定的。想换工具列表?重新创建整个引擎。Astrcode 用 RwLock<Arc<AgentLoop>> 实现运行时热替换:
// replace_surface() — 原子替换 AgentLoop
let _guard = self.runtime.rebuild_lock.lock().await;
let next_loop = build_agent_loop(&next_surface, ...);
*self.runtime.loop_.write().await = next_loop; // 原子替换MCP 服务器新连接、插件热加载、配置变更——不需要重启服务。正在运行的 turn 通过 Arc 引用计数安全持有旧版本,下一个 turn 自动使用新配置。这个能力是 Rust 的所有权系统给的——Arc 保证了旧引用不会被提前释放。
核心循环:同样的逻辑,不同的组织方式
两个系统的核心循环做的是同一件事:LLM 调用 → 工具执行 → 循环。但组织方式完全不同。
Claude Code 的 7 个 continue 站点全在一个函数里:
while (true) {
// ... 365-520 行:消息准备(四级压缩)
// ... 559-863 行:流式 API 调用 + 工具执行
// ... 7 个 continue 分散在各处
// ... 每个都是不同的恢复路径
}Astrcode 的 turn_runner 只做调度,逻辑在三个独立模块里:
'step: loop {
let output = llm_cycle::generate_response(...).await; // LLM 调用
if output.finish_reason.is_max_tokens() { continue } // 截断恢复
if tool_calls.is_empty() { break } // 正常结束
tool_cycle::execute_tool_calls(...).await; // 工具执行
step_index += 1;
}循环体里没有压缩逻辑(在 CompactionRuntime 里)、没有策略检查(在 PolicyEngine 里)、没有权限判断(在 ApprovalBroker 里)。每个模块可以通过 mock 独立测试——这对 Rust 尤其重要,因为编译时间惩罚全量集成测试。
对比总结
| 维度 | Claude Code queryLoop() | Astrcode AgentLoop |
|---|---|---|
| 语言 | TypeScript + Node.js | Rust + tokio |
| 代码组织 | 1400 行巨型函数 | 8 个独立组件 + 3 个子模块 |
| 状态管理 | 散变量 + 就地修改 | 每个组件独立持有状态 |
| 错误恢复 | 7 个 continue 站点,隐式分类 | 结构化 match + Result<T, E> |
| 策略控制 | canUseTool() 散落在循环中 | 独立 PolicyEngine trait,可插拔 |
| 工具调度 | partitionToolCalls() 内联 | 独立 tool_cycle 模块,同样分区并发 |
| 可测试性 | 极难单测 1400 行循环 | 每个组件可独立 mock 和测试 |
| 热替换 | 不支持 | RwLock<Arc<AgentLoop>> 原子替换 |
Claude Code 是"从实践中长出来的"——Node.js 单线程的宽容让它能用一个巨型函数迭代出极致的优化。Astrcode 是"被 Rust 逼出来的最佳实践"——所有权、错误处理、编译时间这些约束,反而迫使架构变得更模块化、更可测试、更可扩展。